



In data science, workloads often involve massive datasets with hundreds of megabytes or gigabytes in memory. This is where Python’s dynamic typing and object wrappers can become a bottleneck. Each Python object (for example, floats in a list or DataFrame columns) carries significant per-object memory overhead and must be tracked by the garbage collector (GC).
Rust, in contrast, compiles directly to machine code and works with contiguous memory layouts similar to C or C++. This allows libraries written in Rust (such as Polars, Arrow, or DataFusion) to handle tabular and numerical data far more efficiently, especially when scanning or aggregating large files.
Because memory is managed at compile time without GC pauses, Rust-based data frames can stream and process data in a cache-friendly, vectorized manner with minimal allocations.
- Libraries like
pandasusenumpy, have a C-based backend. - Or
polarswhich has a Rust-based backend.
DataTUI - the data Terminal User Interface (TUI) for exploration
DataTUI is great for exploration tasks. Quickly load an unfamiliar dataset. Let's say a set of annual reports for various equities.
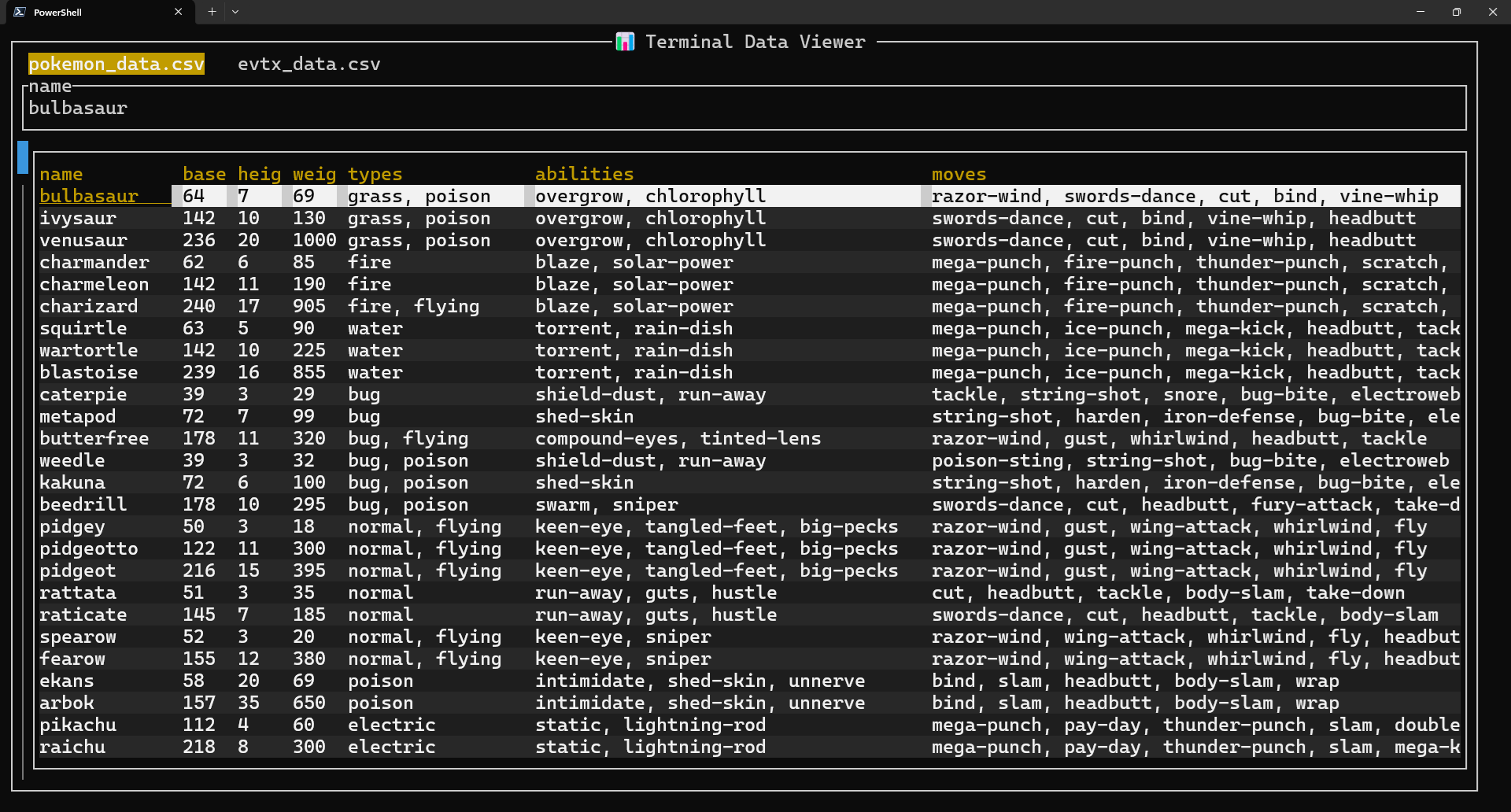
polarsbased- keyboard TUI
- wide-range file support
- allows you to skip complex OLAP / DWH solutions for medium-scale data
- closes a gap
- with a little upkilling you can use it for PowerQuery / DEX style workflows (known from Excel / PowerBI) and accelerate your workflow
Problem: no memory spilling. You may need a beefy laptop / host.
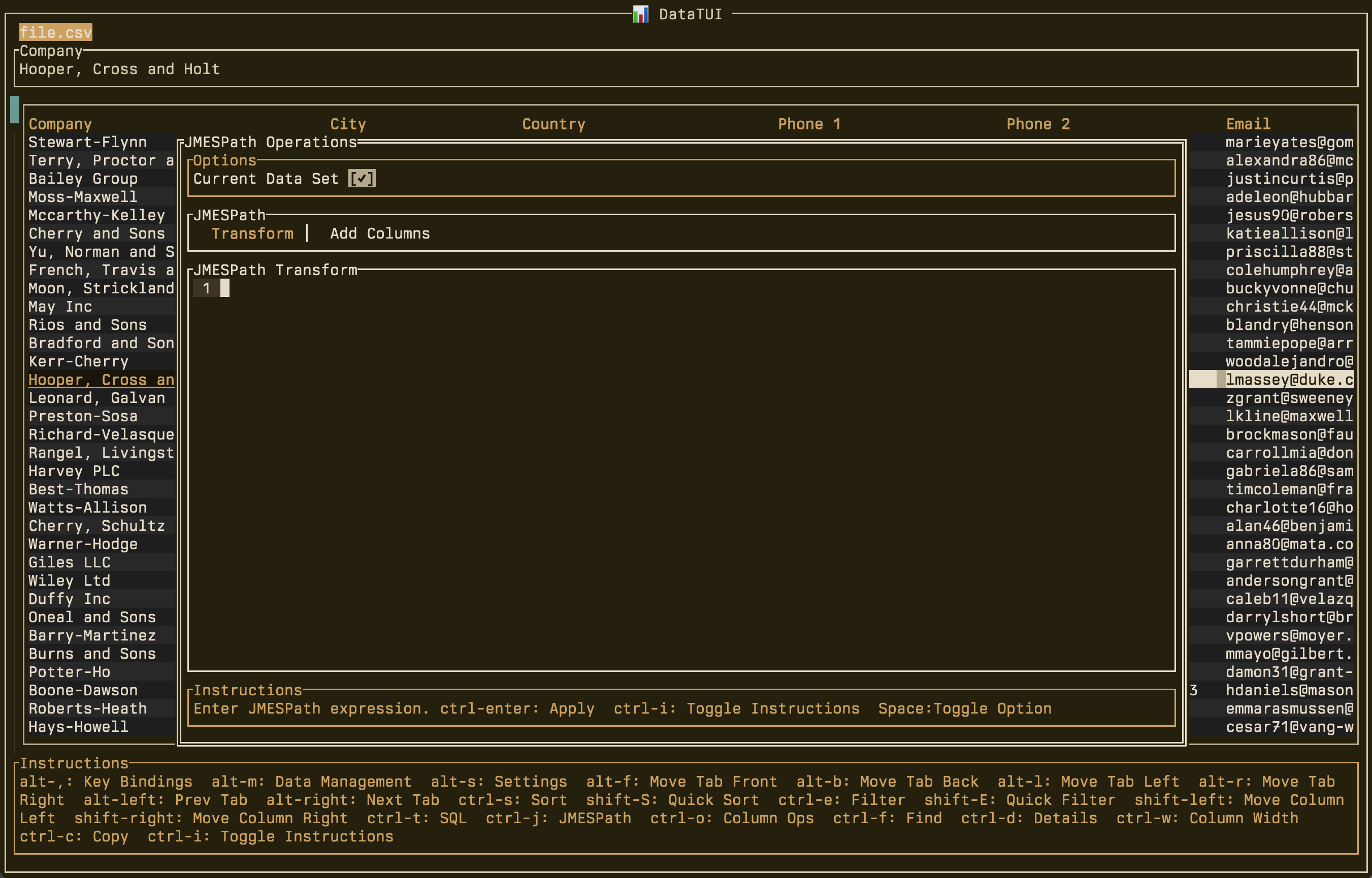
datatui has some advanced features (note: synthetic data).datatui --load 'csv:file.csv'
Visidata is the Python equivalent and uses Pandas 1.x
pandas2 comes with performance improvements, but these do not seem to include memory spilling. Personally, I find it highly annoying because it would be relatively easy to do. Instead, the Pandas project recommends chunking.

visidata therefore has no value-add anymore.
DuckDB
Given the shortcomings of many pandas and polars based projects, I prefer to use DuckDB or ArcticDB
- DuckDB with a memory limit solves the data spilling topic
- ArcticDB can use an LMDB backend on disk and is effective for
pandasflows

For me, the winner is duckdb if the filesize > 60% RAM.




